Depth Anything V3とは?
DepthAnythingV3(DA3)の概要は以下の通り(Geminiにまとめてもらった)。
2025年11月に発表された Depth Anything V3 (DA3) は、従来の単眼深度推定(1枚の画像から深さを測る)の枠を超え、「あらゆる視点数(Any-view)」から一貫した3D空間を復元できる 汎用的な基盤モデルへと進化しました。
主な特徴と、前モデルや他技術との違いを整理して解説します。
Depth Anything V3 の主な特徴
「単眼」から「マルチビュー」への拡張
V2までは主に1枚の画像からの深度推定に特化していましたが、V3は複数枚の画像(マルチビュー)を同時に入力し、それらすべてで矛盾のない(空間的一貫性のある)深度とカメラポーズを推定できるようになりました。
独自の「Depth-Ray(深度レイ)」表現
従来のモデルが「各ピクセルの距離(Disparity/Depth)」のみを予測していたのに対し、V3は「深度マップ」と「レイマップ(光線の方向)」を同時に予測します。これにより、複雑な多タスク学習を必要とせず、単一のトランスフォーマーで精緻な3D点群やガウシアン・スプラッティング(3DGS)の生成が可能になりました。
極めてシンプルなアーキテクチャ
「最小限のモデリング」を追求しており、DINOv2のような標準的なVision Transformer (ViT) をバックボーンとしてそのまま使用しています。特殊な構造を追加せず、アテンション機構(Input-adaptive cross-view attention)を工夫することで、入力画像が何枚であっても柔軟に処理できるスケーラビリティを実現しました。
DA3でできる主なこと
「あらゆる視点」からの3D復元
従来のモデルは1枚ずつの処理でしたが、DA3は「単一画像」「複数枚の画像」「動画」のどれからでも、空間的に矛盾のない立体データを生成できます。
一貫した奥行き: 複数の写真から作った3Dモデルがズレることなく、綺麗に繋がります。
カメラ位置の推定: 写真を撮ったカメラの場所や角度(カメラポーズ)をAIが自動で計算します。
高精度な3Dコンテンツ制作
写真や動画から、プロが使うような3Dデータ(点群やメッシュ)を高速に生成できます。
3D Gaussian Splatting (3DGS): 最新の3D描画技術に対応しており、写真のようにリアルな立体シーンを直接書き出せます。
動画の3D化: ドローン映像や歩きながら撮った動画を、そのまま歩き回れる3D空間へと変換可能です。
大規模な空間マッピング (SLAM)
ロボットや自動運転に不可欠な「自分の場所を把握しながら地図を作る(SLAM)」性能が飛躍的に向上しました。
ドリフト(誤差)の抑制: 広い場所を移動しても位置情報のズレが非常に少なく、従来の専門的な解析ソフト(COLMAP等)が48時間かかる処理を、DA3は一瞬で、かつ高精度にこなします。
DA3の使い方
DA3はpip等でインストールする方法の他、huggingfaceにデモが公開されていたり、blenderから使えるAdd-on、ros2のwrapperなどなど、様々な利用方法が用意されている。この中でも最も簡単に使えるのがhuggingfaceのデモであるが、Multi_Viewを試そうとするとすぐに「Your ZeroGPU daily quota has been exceeded!」となってしまいデモを試すことができない。
また筆者の環境では、blenderから使えるAdd-onは(色々がんばったものの)導入があまり簡単ではなかった。そこで色々検討した結果、ComfyUI(※)上でDA3を動かすのが最も容易であると結論付けた。本記事では、ComfyUIのインストールと、DA3を実行するためのカスタムノードの導入手順について説明する。
※:画像生成AI(Stable Diffusionなど)を動かすための「ノードベース」のユーザーインターフェース(UI)ソフト
ComfyUIの環境構築手順
Step1:ComfyUIの入手
まず最初に、ComfyUI本体の7zファイルを以下のリンク先から入手し、解凍する。
github.com/Comfy-Org/ComfyUI/releases
※:ComfyUI_windows_portable_amd.7z、ComfyUI_windows_portable_nvidia.7z、ComfyUI_windows_portable_nvidia_cu126.7z、ComfyUI_windows_portable_nvidia_cu128.7zの4つが入手できるが、どれをダウンロードするべきかは各自の環境に応じて選択する。nvidia製のGPUが載ったPCならComfyUI_windows_portable_nvidia.7z、AMD製のGPUならComfyUI_windows_portable_amd.7を選ぶとよさそうである。
なお、筆者の動作確認環境(詳細は後述)にはGPUが搭載されていないので、CPUのみで処理を行う必要がある。CPUのみで処理をする場合はどのファイルをダウンロードしてもよいそうである(Gemini曰く)が、筆者はComfyUI_windows_portable_nvidia.7zをダウンロードした。
Step2:ComfyUIの初回起動
Windowsの場合、7zファイルを解凍してできたファイルから「run_*.bat」をダブルクリックで実行する。なお、筆者のようにCPUのみで動作させる場合は「run_cpu.bat」を実行する。
初回起動時は必要なファイルのダウンロードが行われるため、少し時間がかかるので気長に待つこと。しばらく経ってブラウザが自動で開き、ノードが並んだ画面(※)が表示されれば初回起動に成功したと判断できる。
※:ブラウザ上で勝手に開かれる画面がComfyUIの画面である。
Step3:カスタムノードManagerの導入
拡張機能(カスタムノード)を簡単にインストールするために、Managerを導入する。
Managerの導入に当たっては、Managerのソースコード等をダウンロードして適切なディレクトリにファイルを配置し、ComfyUIを再起動すればよい。
方法①:git導入済みの場合
ComfyUI/custom_nodes フォルダ内で右クリックし、「ターミナルで開く」を選択する。
次に以下のコマンドをコピーして貼り付け、Enterキーを押す。
git clone https://github.com/ltdrdata/ComfyUI-Manager.git ※Gitをインストールしていない場合は、リンク先からZIPでダウンロードして custom_nodes に展開してください。最後に、ComfyUIを実行しているターミナルを閉じ、再度 run_*.bat を起動する。再起動すると画面右側に「Manager」ボタンが現れる。
方法②:gitがない場合
github.com/ltdrdata/ComfyUI-Manager.gitを開き、画面右上にある緑の<>Codeボタンをクリックし、Download ZIPを選択する。
次に、ダウンロードしたZIPファイルを解凍し、ComfyUI/custom_nodes フォルダに解凍してできたフォルダを格納する。
最後に、ComfyUIを実行しているターミナルを閉じ、再度 run_*.bat を起動する。再起動すると画面右側に「Manager」ボタンが現れる。
Step4:カスタムノードの導入
run_*.bat を再起動したあと、ブラウザに表示された画面を見ると以下の画像のように画面右上にManagerボタンが追加されている。
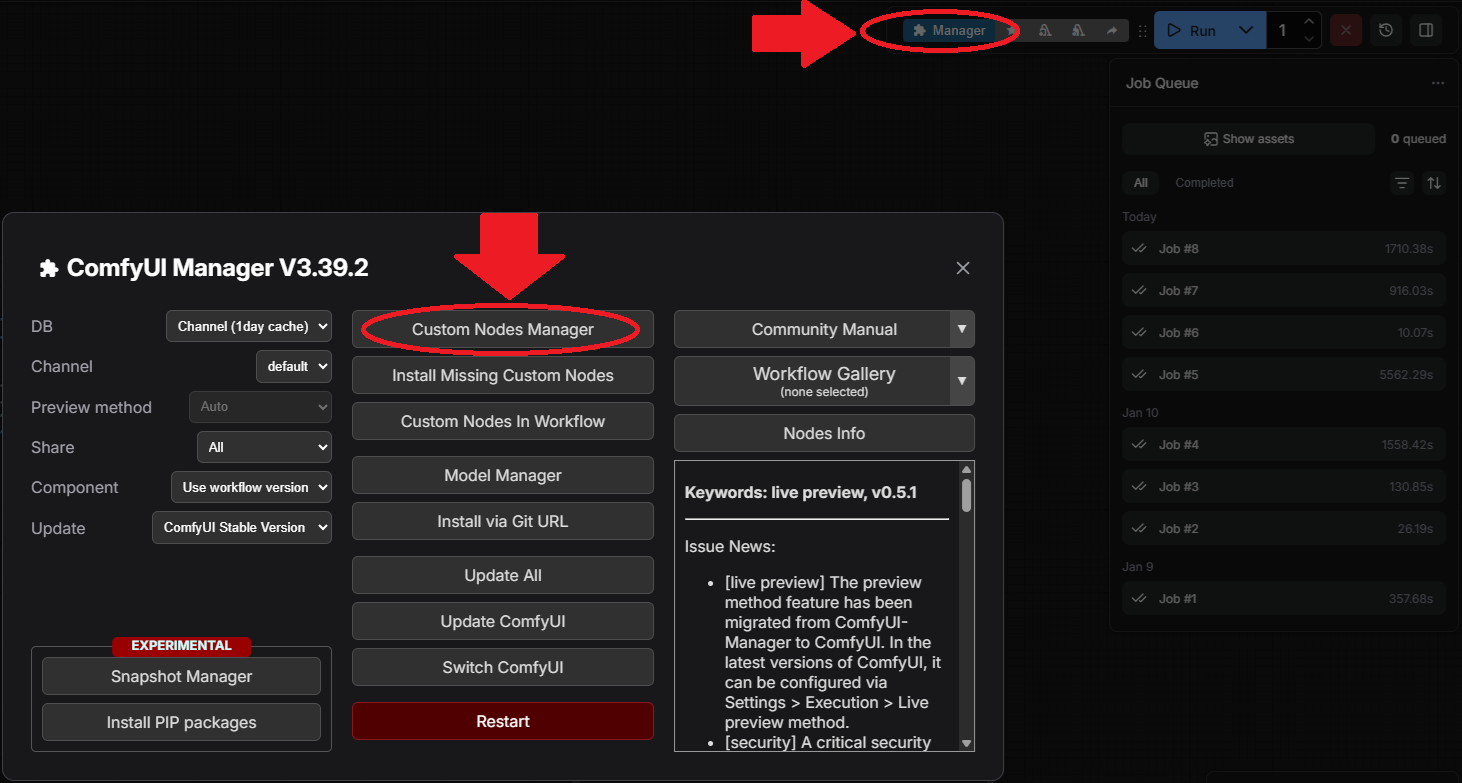
上の画像のように、Manager→CustomNodeManagerを選択すると、以下の画面が表示される。Search欄に導入したいカスタムノード名を入力し、導入したいカスタムノードにチェックを入れてInstallする。なお、カスタムノードを有効にするためには再度run_*.bat を再起動する必要がある。
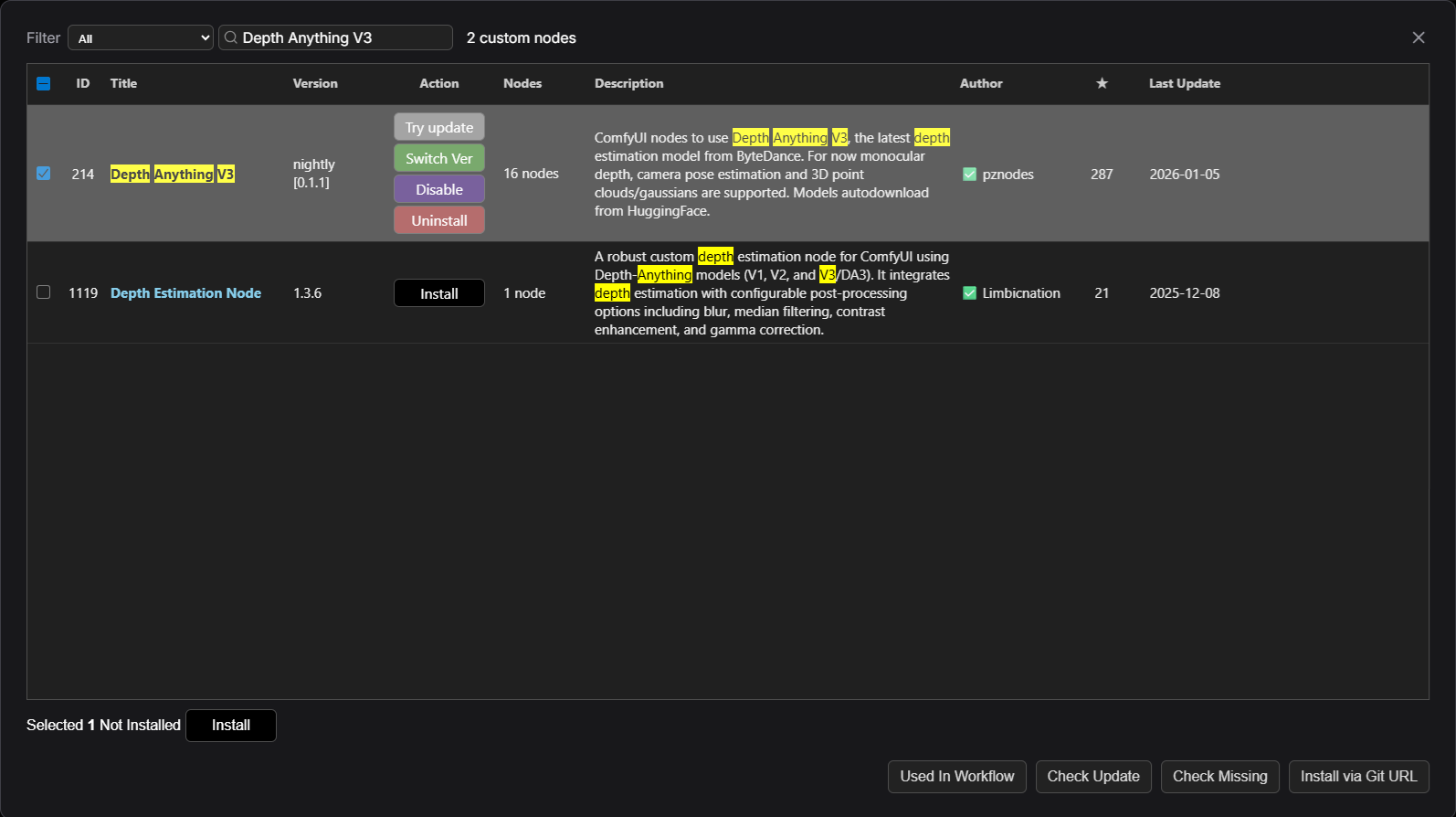
①Depth Anything V3のカスタムノードをインストール
CustomNodeManagerの検索窓に「Depth Anything V3」と入力する。するとComfyUI-DepthAnythingV3 (作成者: PozzettiAndrea) があるので、これを「Install」する。
②VideoHelperSuiteのカスタムノードをインストール
Depth Anything V3でMulti Imageをやるためにはフォルダごと読み込むなどの処理が必要である。色々調べたが標準のノードではうまくできなかったのでカスタムノード「VideoHelperSuite」を入れるのがよさそうである。
インストールに当たっては、CustomNodeManagerの検索窓に「VideoHelperSuite」と入力し「Install」する。
③「run_*.bat」を再起動する
カスタムノードをインストールしたら、画面にも表示されるが忘れずにComfyUIを再起動する。環境構築は以上。
Depth Anything V3の実行
以上の手順により(ようやく)DA3が実行できるようになる。本記事ではシンプルな機能の使い方(single image to 3D/ multiple image to 3D)について説明する。本記事では説明しない、詳細なオプションや機能については以下のリンク先(github.com/PozzettiAndrea/ComfyUI-DepthAnythingV3)を参照するとよい。
Single Image to 3D:単一の画像から点群を生成する
ノードの追加
画面を右クリックし、Add Nodeからノードを配置する。
①Add Node > image > Load Image で元画像を読み込むノードを配置する。「choose file to upload」で写真を選択することができる。
②Add Node > image > upscaling >Upscale Image Byを追加する。公式の手順には本ノードが記載されていないが、このノードを用いて画像の解像度を適切に調整しないと処理時間がめちゃくちゃ長くなる。
③Add Node > DepthAnythingV3 > (down)Load Depth Anything V3 Modelを追加する。Modelは好きなものを選択すればよいが、デフォルトのまま(da3_large.safetensors)でも特段問題ない。初回実行時にモデルがダウンロードされるので、初めてのモデルを選択した際は少し時間がかかる。
④Add Node > DepthAnythingV3 > DepthAnythingV3を追加する。
⑤Add Node > DepthAnythingV3 > DA3 to Point Cloudを追加する。
⑥Add Node > DepthAnythingV3 > DA3 Save Point Cloudを追加する。
⑦(オプション:必要なら)Add Node > DepthAnythingV3 > DA3 Preview Point Cloud/ Gaussiansを追加する。
ノードの接続とパラメータの設定
以下の画像を参考に各ノードを接続し、パラメータを設定する。なお、Upscale Image Byノード(※)は入力された画像のピクセル数をscale_byの値でかけた値の画像を出力する。例えば、入力画像が1000×500[px]、scale_byが0.5なら、出力画像は500×250[px]となる。
※:本来は画像を拡大するノードだが、scale_byの値を1以下にすると縮小もできる。
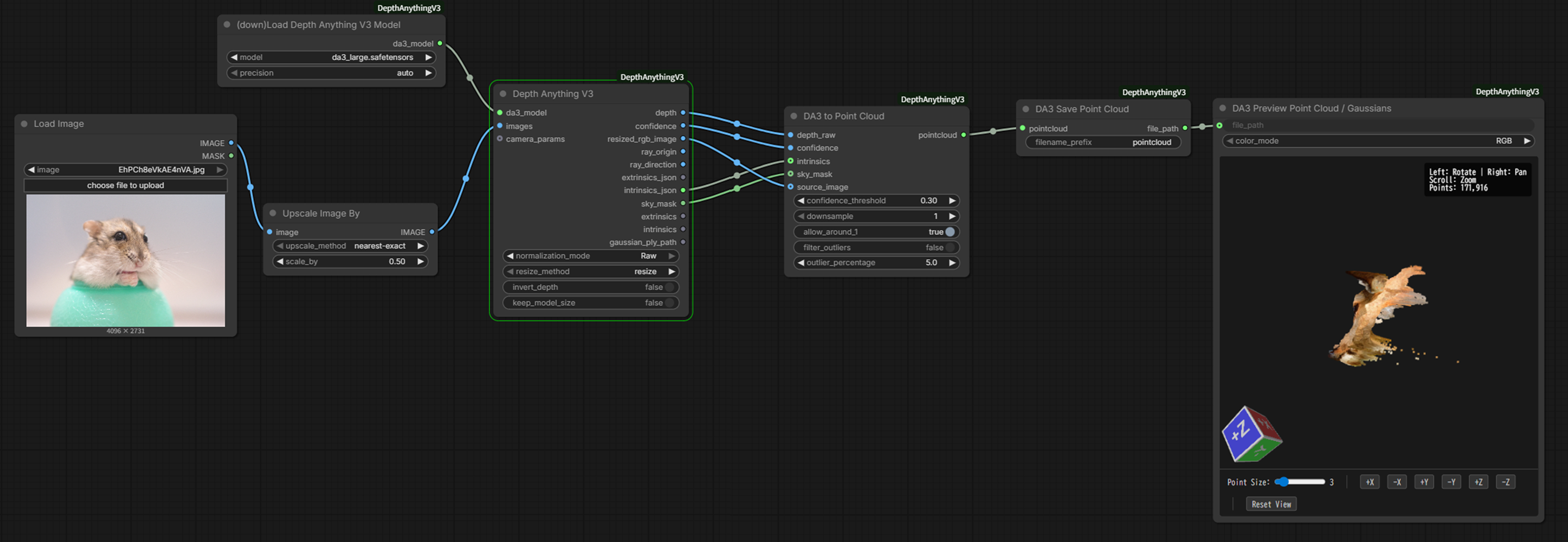
実行
画面右側の 「Queue Prompt」 をクリックする。
先述の通り、初回実行時はモデル(数百MB〜数GB)の自動ダウンロードが始まる。現在処理中のノードの色が変わるので、終了するまでしばらく待つ。
実行結果は、本記事の画像の通りの設定の場合、「ComfyUI_windows_portable/ComfyUI/output」ディレクトリ下にply形式で保存される。
実行した例を以下に示す。
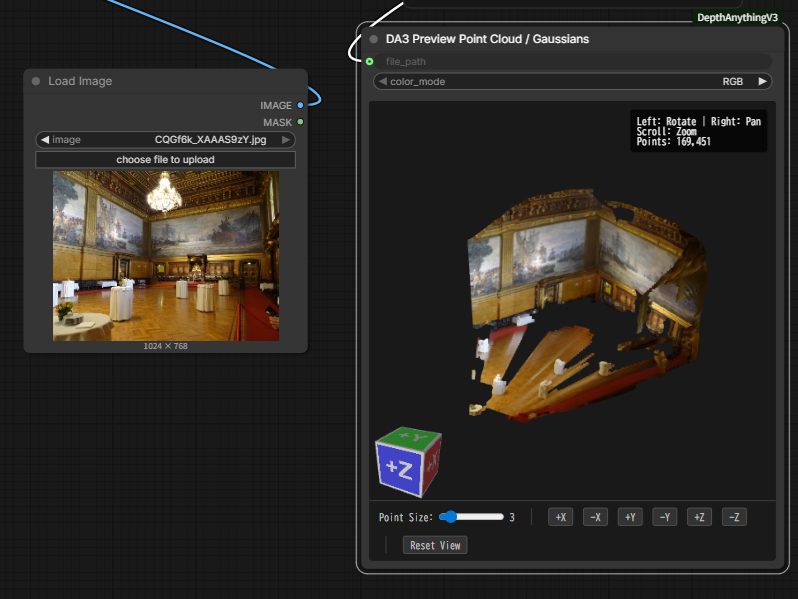
Multiple Image to 3D:複数の画像から点群を生成する
ノードの追加
画面を右クリックし、Add Nodeからノードを配置する。以下の青いアンダーラインで示す通り、半分くらいはSingle Image to 3Dと同じである。
①Add Node > Video Helper Suite > Load Images (Path) で元画像フォルダを読み込むノードを配置する。「directory」欄にフルパスをテキストで入力することで写真の格納されたフォルダを選択することができる。
②(Single Image to 3Dと同じ手順)Add Node > image > upscaling >Upscale Image Byを追加する。公式の手順には本ノードが記載されていないが、このノードを用いて画像の解像度を適切に調整しないと処理時間がめちゃくちゃ長くなる。
③(Single Image to 3Dと同じ手順)Add Node > DepthAnythingV3 > (down)Load Depth Anything V3 Modelを追加する。Modelは好きなものを選択すればよいが、デフォルトのまま(da3_large.safetensors)でも特段問題ない。初回実行時にモデルがダウンロードされるので、初めてのモデルを選択した際は少し時間がかかる。
④Add Node > DepthAnythingV3 > DepthAnythingV3(Multi-View)を追加する。
⑤Add Node > DepthAnythingV3 > DA3 Multi-View Point Cloudを追加する。
⑥(Single Image to 3Dと同じ手順)Add Node > DepthAnythingV3 > DA3 Save Point Cloudを追加する。
⑦(Single Image to 3Dと同じ手順)(オプション:必要なら)Add Node > DepthAnythingV3 > DA3 Preview Point Cloud/ Gaussiansを追加する。
ノードの接続とパラメータの設定
以下の画像を参考に各ノードを接続し、パラメータを設定する。
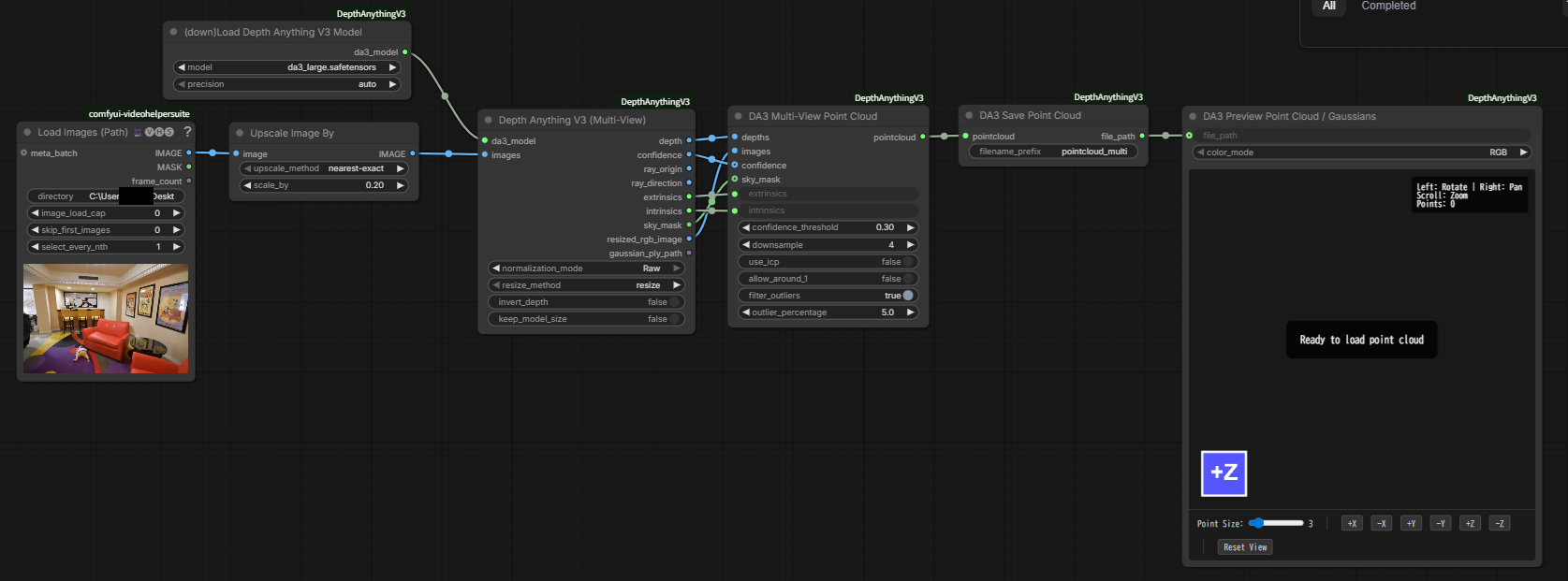
実行
画面右側の 「Queue Prompt」 をクリックする。
実行した例を以下に示す。

なお、実行例については公式の情報/論文を参考にするとよい。
以上。
おまけ
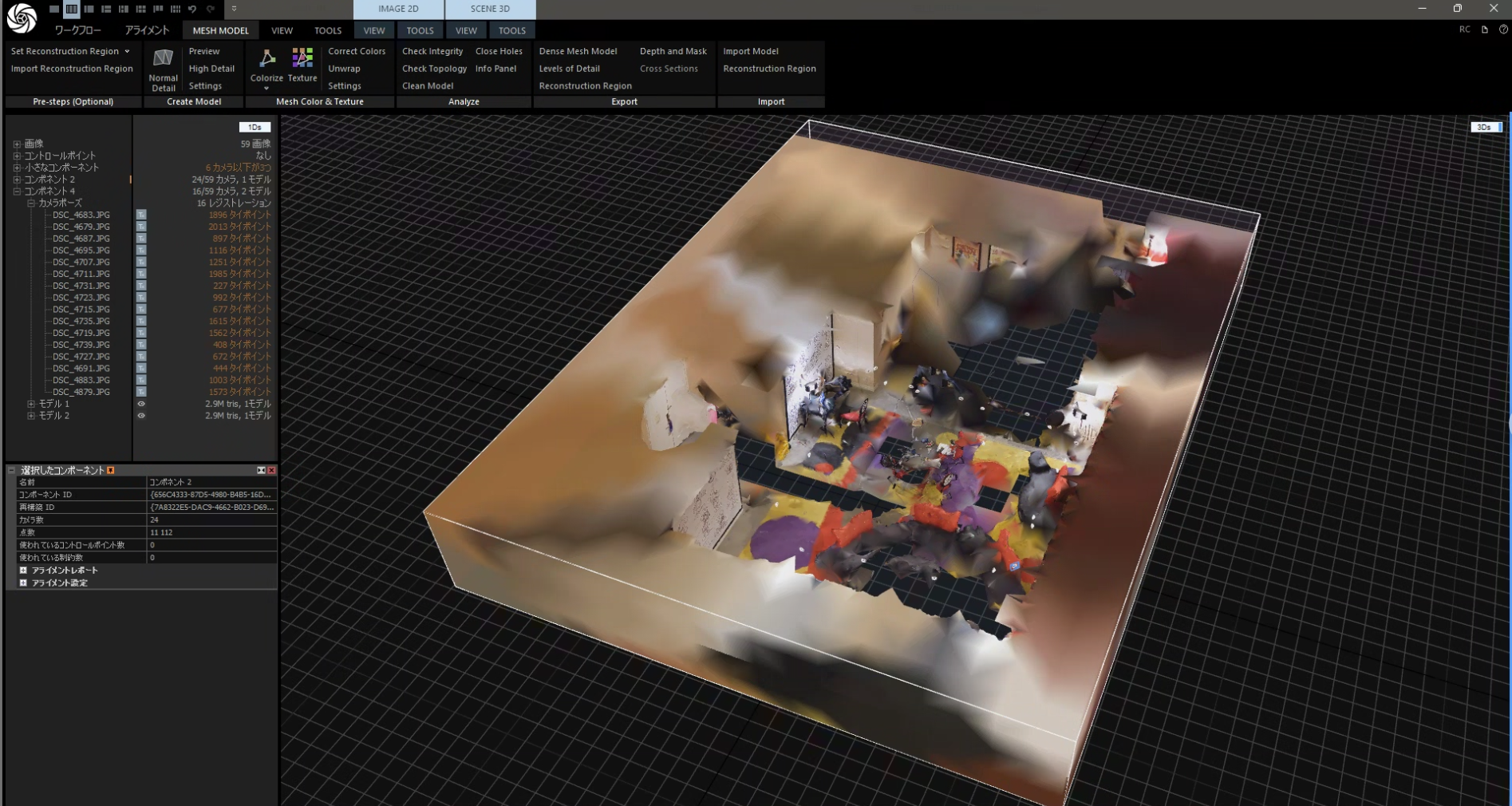
以下に、Multiple image to 3Dで用いたものと同じ画像をReality Scan (Reality Capture)でフォトグラメトリ処理を行った例を示す。画像が50枚程度しかないこともあり、そもそもアライメントがうまくいかなかった(25枚ずつくらいで2つのコンポーネントに分かれてしまった)。あくまでデフォルト設定かつかなり枚数を削減したので、フォトグラメトリソフトでの処理がうまくいかないのはまあ想定通りである。
このような結果から、DA3は簡単に3D化するという目的ではフォトグラメトリ(SfM)に比べて優れた部分があるのではないかと思う。(もちろん、写真撮影のところからきちんと頑張ればフォトグラメトリの方がうまくいくような気もする。)

コメント